Supervised learning in artificial intelligence is like teaching a machine through examples. Just as you guide a child by providing information and feedback, machines learn by analyzing labeled data to predict future outcomes. This approach is rooted in real-world logic, enabling machines to make decisions in uncertain situations.
From spam filters to facial recognition, supervised learning is all around us, yet many use it without realizing it. This article explores the core concepts of supervised learning, how it works, and real-world examples, offering a straightforward explanation of this essential AI technique without complex jargon or buzzwords.
At its core, supervised learning is all about learning patterns with practice. The term describes it all—being "supervised" means the machine is learning under direction. It's similar to having a tutor who provides both the question and the solution in a training session. The model (or the pupil) takes these examples and learns a general rule that converts inputs to outputs.
The entire process begins with a labeled dataset. The dataset has input-output pairs—e.g., a list of images and one label each, whether having a cat or a dog in it. They are presented as inputs to an algorithm that attempts to discover an arithmetic function in terms of features of the input (like pixel values in images) and the expected output (like the animal label).
There are two common branches of supervised learning: classification and regression. Classification is used when the output is a category, like spam or not spam or handwritten digits 0 through 9. Regression is used when the output is a continuous number—predicting house prices, for instance.
Training a supervised learning model involves minimizing the error between the predicted outputs and the actual labels in the training data. This is typically achieved by specifying a "loss function" and employing optimization methods such as gradient descent to minimize it. The model keeps adjusting itself—tweaking internal parameters—until it gets as close as possible to the correct answers on the training data.
Once training is complete, the model is evaluated on unseen data to test its ability to generalize—because memorizing isn’t enough. A good model can take a brand-new input and make a reliable prediction based on what it has learned.
What's powerful about supervised learning is that it's not about rules. Someone writes by hand. Instead, the system learns patterns from data, which makes it scalable to problems where rules are too complex or unknown.
To understand supervised learning, it's helpful to look at real-world examples. One of the most common uses is email filtering. Email systems analyze factors like the sender, the words in the message, and the format, using this information to classify emails as spam or not. These systems are trained on millions of labeled emails, and as they process more, they improve at predicting the classification of future messages.

Another well-known application is facial recognition technology. For instance, a phone trained to recognize its owner’s face uses thousands of labeled images. Some contain the owner's face, while others don't. The algorithm maps facial features to the correct identity, and as it successfully unlocks the phone, it strengthens its predictions. If it fails, it gets feedback, gradually improving.
In healthcare, supervised learning helps diagnose diseases. A model trained on X-ray images labeled as ‘healthy’ or ‘pneumonia’ learns to identify patterns, like cloudiness in the lungs. The model can then predict the likelihood of a disease when analyzing new X-rays, providing valuable insights for doctors.
In finance, supervised learning is used for credit scoring. Models analyze input like income and credit history, with the label being whether a person repaid their loan. The system learns to associate patterns with positive or negative outcomes, helping lenders assess future applicants.
Finally, recommendation systems on platforms like Netflix and Spotify rely on supervised learning. These models use user preferences and behaviors to predict what content you’ll enjoy next, improving as they collect more data.
All these examples share the core idea of learning from labeled data to make future decisions.
While supervised learning has proved to be incredibly powerful, it’s not without limitations. First and foremost is the dependence on high-quality labeled data. You need a lot of it—and labeling it is often expensive, time-consuming, and prone to human error. If your data is flawed, your model will be too. Garbage in, garbage out.
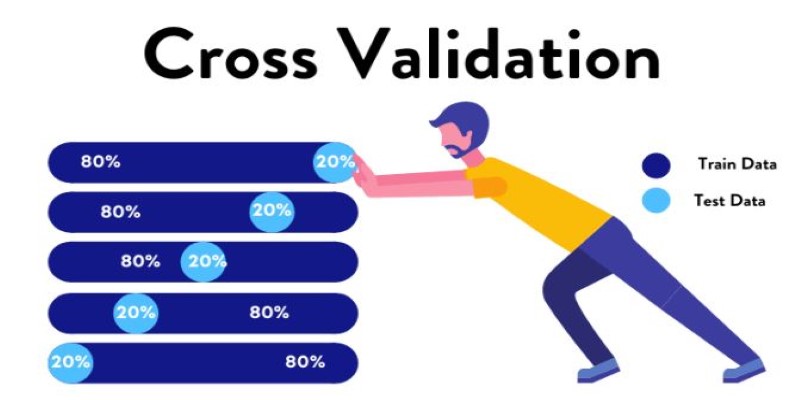
There’s also the risk of overfitting. This happens when a model becomes too good at predicting the training data but fails miserably on new data. It essentially memorizes the answers instead of understanding the underlying patterns. To tackle this, practitioners use techniques like cross-validation and regularization to make models more robust.
Bias in data is another thorny issue. If your training data reflects social biases, your model will too. This is a serious concern in areas like hiring or criminal justice, where skewed predictions can have real-life consequences. Auditing datasets for fairness and using balanced training data becomes essential to prevent harm.
Moreover, supervised learning assumes that future data will follow the same pattern as the training data. But that's not always the case. Imagine a financial model trained on market data before a global crisis—it may not perform well during the crisis simply because the patterns have shifted.
Computational cost is another factor to consider. Training large supervised learning models, especially those with millions of data points, requires significant computing power. This can be a hurdle for smaller organizations or individual developers.
Despite these challenges, the core idea remains remarkably effective. With the right data and methods, supervised learning has consistently delivered practical solutions across countless domains.
Supervised learning remains a cornerstone of modern AI, offering powerful solutions for various real-world problems. Learning from labeled data enables machines to make predictions and classifications, enhancing everything from healthcare to entertainment. Despite challenges like data quality and bias, its ability to learn from examples makes it an invaluable tool in the AI landscape. As data continues to grow, supervised learning's role will only expand, driving further advancements in intelligent systems.

GANs and VAEs demonstrate how synthetic data solves common issues in privacy safety and bias reduction and data availability challenges in AI system development

Discover ChatGPT, what it is, why it has been created, and how to use it for business, education, writing, learning, and more
Business professionals can now access information about Oracle’s AI Agent Studio integrated within Fusion Suite.

Explore surprising AI breakthroughs where machines found creative solutions, outsmarting human expectations in unexpected ways

Know how sentiment analysis boosts your business by understanding customer emotions, improving products, and enhancing marketing
Know the essential distinctions that separate CNNs from GANs as two dominant artificial neural network designs

Learn AI and machine learning for free in 2025 with these top 10+ courses from leading platforms, universities, and tech experts

Explore if AI can be an inventor, how copyright laws apply, and what the future holds for AI-generated creations worldwide

Explore IBM Granite-3.0's setup, features, and real-world uses in AI. Learn to deploy it efficiently for enterprise tasks.

remove duplicate records, verification is a critical step, SSIS provides visual tools

Boost teacher productivity with AI-generated lesson plans. Learn how AI lesson planning tools can save time, enhance lesson quality, and improve classroom engagement. Discover the future of teaching with AI in education

With TensorFlow Extended (TFX), learn sentiment analysis using this comprehensive guide for creating and implementing models